Agora — wenn Sprachmodelle gegeneinander diskutieren, statt nur zu antworten
Wie ich aus MiroFish einen lokal-first Fork mit Neo4j, Ollama und OASIS gebaut habe, was die Vier-Stufen-Pipeline aktuell wirklich kann und welcher Cloud-Modell-Stall mich heute eine Stunde gekostet hat.
- Agora
- GraphRAG
- Neo4j
- Ollama
- Local-First
- Agenten
- Simulation

Worum es geht
Agora ist seit ein paar Wochen mein Hauptprojekt nach Feierabend. Im Kern ist es ein Fork von MiroFish-Offline. Die Idee ist nicht neu, aber für mich genau das Richtige: ein Dokument hochladen, daraus einen Wissensgraphen ziehen, daraus Personas spawnen, die als Agenten auf einer simulierten Plattform diskutieren — und am Ende einen Report bekommen, was die Diskussion an Polarisierung, Bündnissen und Bridge-Agents ergeben hat.
Klingt nach Marketing. Ist es nicht. Es ist im Kern ein Werkzeug, um zu sehen, wie Stakeholder zu einem Thema gegeneinander stehen, bevor man eine Pressemitteilung rauslässt oder einen Bürgerentscheid plant. Oder einfach um neugierig zu spielen.
Warum Fork
MiroFish setzt auf Zep Cloud und auf DashScope bzw. OpenAI. Beides ist für mich kein Setup, das ich hier in Leipzig hinter meinem T7 laufen lassen will. Erstens fließen alle Daten in fremde Rechenzentren. Zweitens kann ich bei Cloud-Modellen ohne Zugriff aufs Routing nicht reproduzierbar arbeiten — und Reproduzierbarkeit ist die halbe Miete bei einer Pipeline mit vier Stufen, in denen jede Stufe von der vorherigen abhängt.
Also: Zep raus, Neo4j 5.18 rein. DashScope/OpenAI raus, Ollama rein — entweder lokal oder über Ollama Cloud, wenn ein Modell wirklich Größe braucht. Embeddings macht aktuell mit 2560 Dimensionen, das LLM ist . Frontend ist Vue 3 + Vite, Backend Flask mit als Package-Manager. Alles in einem -Stack mit Neo4j und Redis daneben.
Das eigentliche Argument ist banal: Ich will jeden Knopf selbst sehen, jedes Log selbst lesen können, und jeden Subprozess wenn nötig mit töten dürfen.
Was die Pipeline kann
Vier Stufen. So sieht der Workspace aus, während sie laufen — links der Wissensgraph, rechts die aktuelle Stufe:
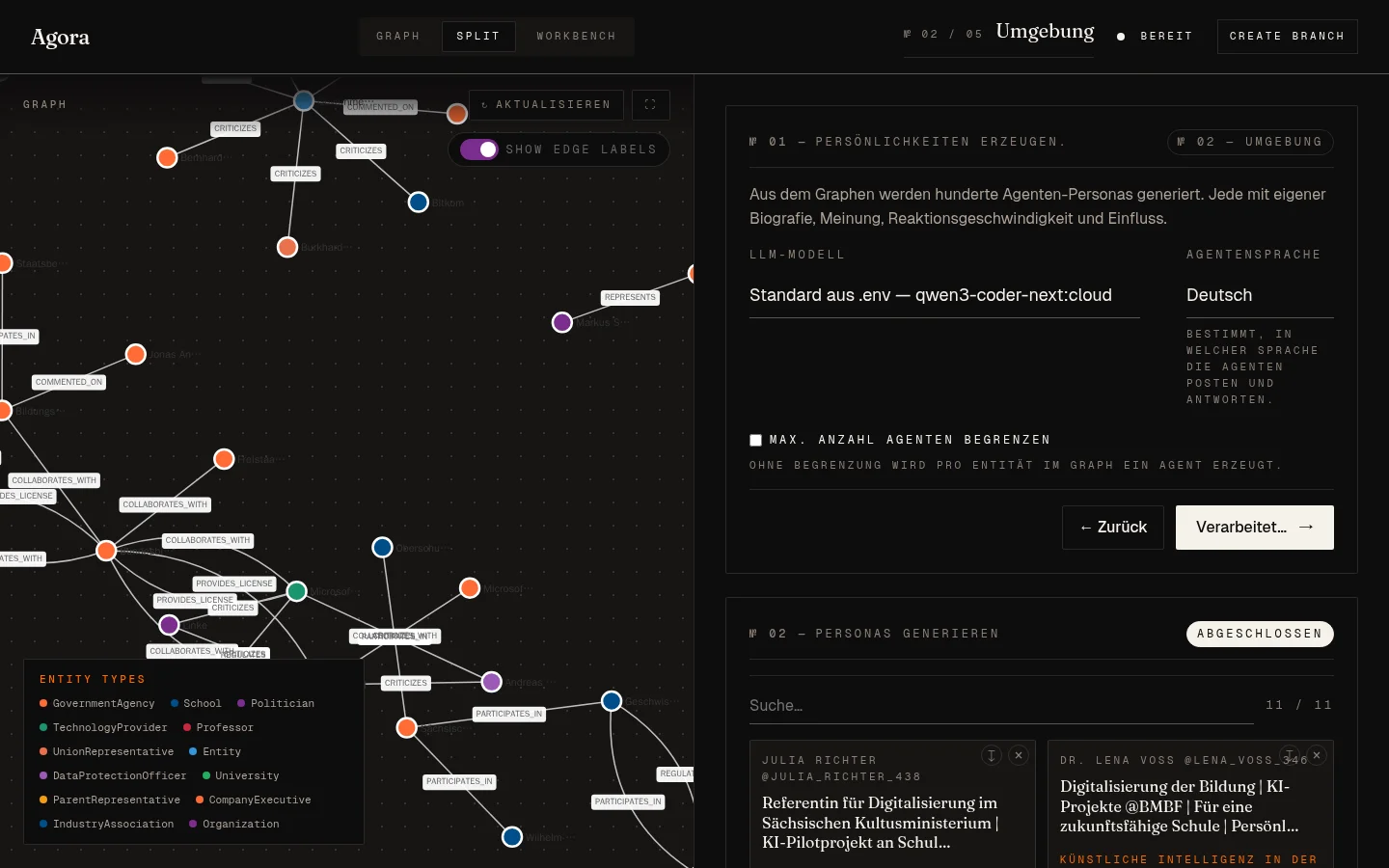
1. Graph Build
Dokument wird gechunkt (1500 Token, 150 Overlap), parallel auf NER und Relation-Extraction geschickt. Die Triples landen mit Embedding und Vektor-Index in Neo4j. Aus einem fiktiven Pressetext zu einem KI-Pilotprojekt in Sachsen wird zum Beispiel das hier:
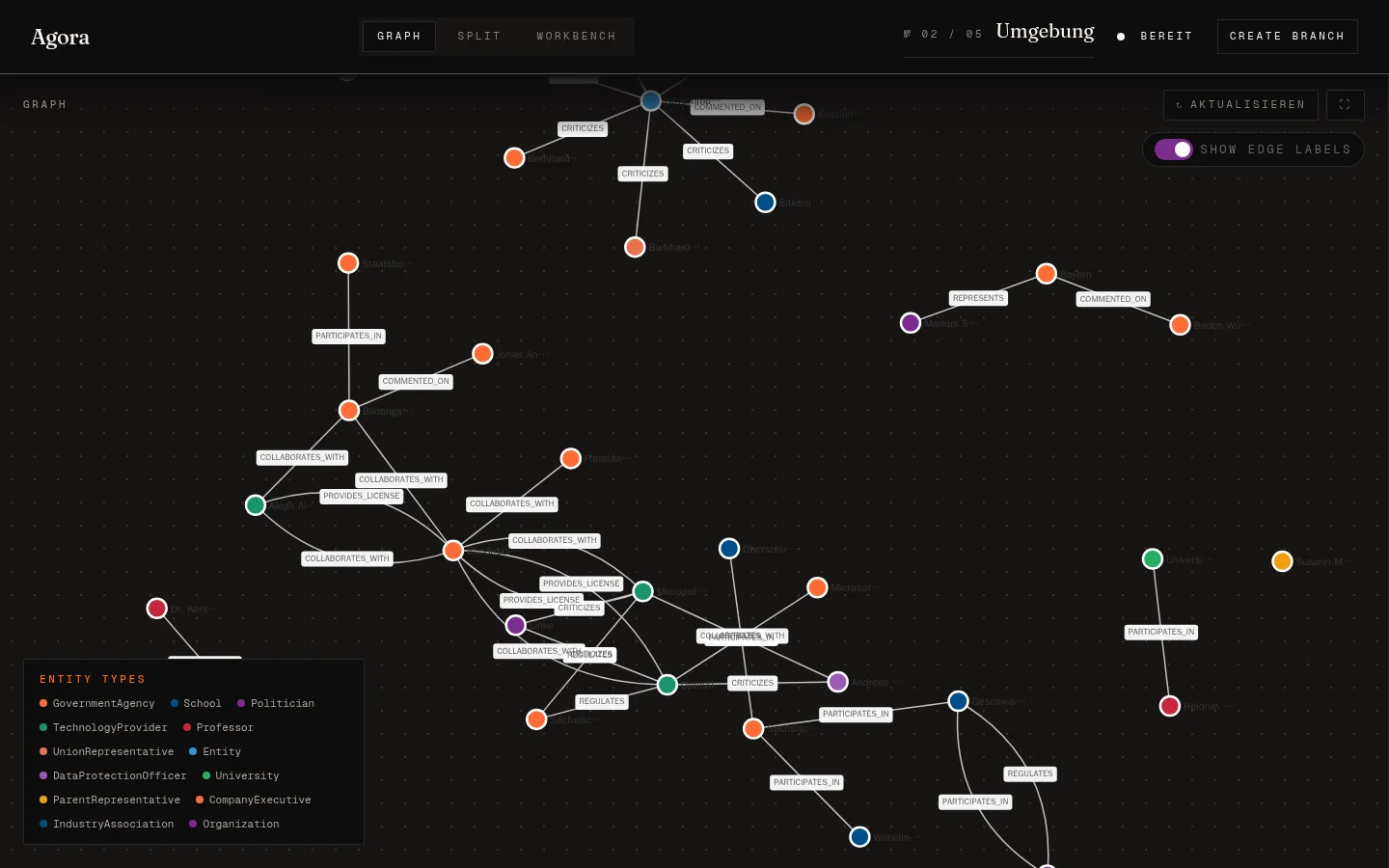
Jeder Knoten ist eine Entität — Politiker, Organisationen, Schulen, Universitäten. Jede Kante eine Relation mit Typ (, , , ). Das Schöne an Neo4j: ich kann jederzeit den Cypher-Editor aufmachen und nachsehen, was wirklich drin steht. Bei einer In-Memory- oder Cloud-Vector-Lösung wäre das deutlich umständlicher.
2. Personas
Aus dem Graph werden Personas generiert. Eine pro Entity-Knoten, wenn man’s nicht kappt. Jede Persona ist ein detailliertes Profil mit MBTI, Beruf, politischer Haltung, Schreibstil, Social-Media-Verhalten. Pro Persona gehen 2–3 LLM-Calls raus.
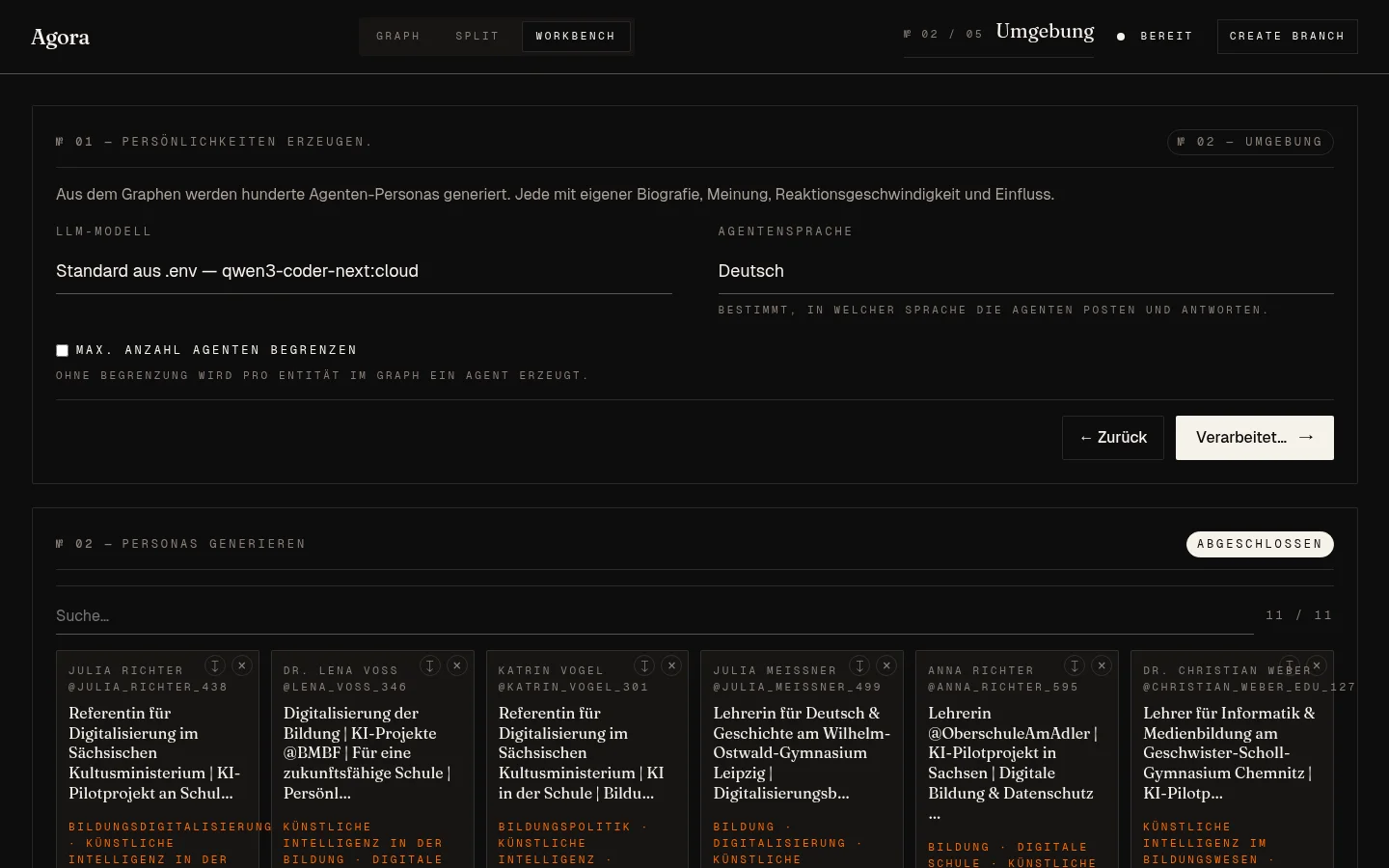
Was mich überrascht hat: Die Persona-Texte sind kohärent. Aus dem Sachsen-Pressetext kam unter anderem eine 42-jährige Bildungsreferentin aus Berlin, ENFJ, Twitter-affin, mit Sympathie für interoperable Lösungen und Skepsis gegenüber OpenAI-Lock-in. Klingt nach Klischee — aber alle Felder hingen logisch zusammen, und sie hat in der späteren Simulation auch genau diese Linie gefahren.
3. Simulation
OASIS läuft als separater Subprozess. Flask redet mit dem Subprozess über einen Event-Bus — File-Polling als Fallback, Redis Pub/Sub als schneller Pfad. Pro Runde dürfen die Personas posten, replyen, retweeten. Der Polarisierungs-Service liefert über und Louvain-Community-Detection sinnvolle Cluster — wenn die Personas divers genug sind.
4. Report
Ein Report-Agent geht mit Tool-Use durch den Graph und die Simulationsergebnisse und schreibt einen Bericht. Optional kommt Tavily für Live-Web-Kontext dazu.
Die Sache, an der ich am meisten Freude habe, ist die Temporal-Graph-Funktion: Du kannst dir Round-für-Round-Snapshots der -Kanten anschauen und sehen, wie sich Bündnisse während der Simulation umbauen. Eine Kante hat und ; ein Round-Slider im Frontend filtert clientseitig — kein zusätzlicher API-Round-Trip beim Scrubben.
Was wehtut
Ich will nicht so tun, als sei das Production-Ready. Ist es nicht. Aktueller Stand: v0.6.1 alpha, Unreleased Richtung v0.7.
- Die Frontend-API-Schicht ist großteils noch plain JavaScript. TypeScript-PoC läuft (, mit ), aber die Migration ist nicht durch. Ich suche bei den Polling-Endpoints und dem SSE-Stream zu oft in den DevTools nach Tippfehlern.
- API-Error-Envelopes sind angefangen, aber nicht überall durchgezogen. Auth-Fehler, der -Decorator und Framework-404/405 liefern jetzt sauber . Der Rest der Endpoints muss noch nachziehen.
- Cloud-Modelle haben sporadische Stalls. hat mich heute eine Stunde lang im Kreis pollen lassen, weil ein Persona-LLM-Call ohne Response hing. Retry-Logik fängt 5xx, aber gegen einen kompletten Stall ist kein Kraut gewachsen außer Modell-Wechsel. Lehrgeld. Mit lief der gleiche Run anschließend in unter vier Minuten durch.
- Der File-IPC-Pfad zwischen Flask und OASIS soll deprecated werden, sobald die Telemetrie zeigt, dass die Redis-Bridge in allen Setups stabil läuft. Aktuell laufen beide Pfade parallel als Race, der Verlierer wird aufgeräumt — funktioniert, ist aber kein Endzustand.
- Die Persona-Filterung lässt aktuell auch Schulen, Industrieverbände und einige andere Nicht-Personen-Entitäten durch, weil die Ontologie sie als eigene Klasse führt. Eine Schule ist keine Stimme. Muss ich rausziehen oder als kollektive Stimme anders modellieren.
Was als Nächstes kommt
Drei Sachen, in dieser Reihenfolge:
- Persona-Filter härten. Nur noch Entity-Klassen, die plausibel eine Stimme haben — , , , , , . Schulen, Behörden und Verbände rauswerfen oder als „kollektive Stimme” anders modellieren.
- Frontend-API auf TypeScript. Inklusive handgepflegter Typen für die Polling-Endpoints und den SSE-Stream, damit der Loop nicht jedes Mal manuell synchronisiert werden muss.
- API-Response-Envelope vereinheitlichen. als verbindliches Format auf allen -Endpoints, damit das Frontend nicht für jede Stufe einen eigenen Edge-Case-Parser braucht. Wenn das durch ist, kommt der Schritt, auf den ich mich am meisten freue: Agora gegen ein echtes Dokument fahren — ein bildungspolitisches Positionspapier, eine Pressemitteilung, einen Bürgerentscheid-Leitfaden — und sehen, wie nah die simulierte Reaktion an dem ist, was eine Woche später wirklich auf X passiert.
Das ist die Hypothese, an der ich arbeite: Wenn man Sprachmodelle gegen sich selbst diskutieren lässt, mit ehrlichen Persona-Profilen und echten Daten als Anker, sieht man Polarisierungstendenzen früher. Ob das wirklich trägt, weiß ich noch nicht. Aber das ist der Test, auf den ich hinarbeite.
Code liegt aktuell auf meinem T7 in . Wenn die API-Schicht durch ist und der Persona-Filter sauber, geht der Fork öffentlich auf GitHub. Vorher nicht — ich will keinen halben Stand verteilen.
Wer mit ähnlichen Setups spielt (Neo4j + Ollama + agentenbasierte Simulation), schreibt mir gerne. Ich bin in den üblichen FISI- und Selfhosted-Communities unterwegs.
Weiterlesen